
Heroku の無料プランが11月28日で終了します。Heroku Dynosは月額7ドルの有料プランに移行できるのですが、現在利用しているのは Node.js アプリ1つですので、他に無料でできるのであればそれに越したことはありません。Node.js でやっているのはウェブスクレイピングですので python でやれば、WordPress を立ち上げているレンタルサーバー内で作業を完了できるのではないかということです。
- Filmarks サイトから自分の投稿アドレスを取得する
- 過去:はてなブログから Heroku の Node.js を呼ぶ
- Ajax -> php -> python -> php -> Ajax
- python スクリプト
01Filmarks サイトから自分の投稿アドレスを取得する
現在 Node.js を利用しているのは次のサイトの各記事の本文下に置いている Filmarks のリンクです。

このサイトは映画のレビューサイトであり、リンクは該当記事と同じ映画の Filmarks の自分のレビューページに飛ぶようになっています。
やっていることは、
- Javascript で該当ページのタイトルを取得し、Heroku の Node.js サーバに投げる
- Node.js サーバーは、Filmarks のマイページをスクレイピングして該当タイトルのレビューがあればそのアドレスを返す
- Filmarks ボタンがクリックされた場合はそのアドレスの Filmarks レビューページを別タブで開く
ということです。
02過去:はてなブログから Heroku の Node.js を呼ぶ
現在は、このブログを含めすべて WordPress に移行していますが、半年ほど前までははてなブログで運用していました。ですので、ブログになにか機能を追加しようとすれば Javascript しかなく、ただ、Javascript で外部サイトにアクセスしてもオリジン間リソース共有 (CORS)エラーでデータは取得できません。ということで Heroku で Node.js サーバーを立ち上げていたということです。
その経緯は次の記事にあります。
上のように Glitch でもよかったのですが、結局使い慣れた Heroku で立ち上げたということです。その後、はてなブログから WordPress に移行したのですが、現在もそのままの状態でHeroku の Node.js サーバーで運用しているということです。
03Ajax -> php -> python -> php -> Ajax
で、これを WordPress を立ち上げているレンタルサーバー内で完了させるように python でやってみようと思います。
当然まずはローカル環境で試してみようということですが、現在 WordPress のローカル環境は Docker で構築していますので python を使うことが出来ません(多分)。ですので、php と python の連携はコンソール上で確認し、Ajax は Docker 上の WordPress で確認して、OK ならレンタルサーバー上でやってみようという考えです。
php のテスト用スクリプト
<?php
$title = $argv[1];
$command = 'python3 ./get_filmarks_page.py "' . $title . '"';
exec( $command, $output );
echo $output[0] . PHP_EOL;
die;コマンドラインから映画タイトルを引数で受け取り、同じディレクトリにある python のスクリプト get_filmarks_page.py に引数として渡して呼ぶだけです。戻り値を $output で受け取り表示します。
04python スクリプト
python を使ったウェブスクレイピングは過去に次の記事で試しています。
ですので、requests, beautifulsoup4, lxml, re はインストールされているものとします。また、以下ではパースの方法なども説明していませんので上記の記事を参照してください。
import sys
import requests
from bs4 import BeautifulSoup
import re
title = sys.argv[1]
url = 'https://filmarks.com/users/ausnichts'
html = requests.get(url).text
soup = BeautifulSoup(html, 'lxml')
found = soup.select_one('.c-pagination__last')
href = found.get('href')
page = re.match('.*page=(\d+)$', href)
last = int(page.group(1)) + 1
for i in range(1, last):
u = url + '?page=' + str(i)
html = requests.get(u).text
soup = BeautifulSoup(html, 'lxml')
links = soup.select('.c-content-card__title > a')
for link in links:
if title in link:
print(link.get('href'))
sys.exit()- コマンドライン引数を受け取るには sys ライブラリが必要です。
- url は私の filmarks マイページのアドレスです。
- マイページは1ページに36記事掲載され、ページネーションのラストページのリンクが総ページ数をもっていますので正規表現を使って変数 page に取り出します。
- for in で1ページから総ページ数を越えない回数読み込みを繰り返します。
- 各ページで記事タイトルのリンク要素36個を取り出し、1つずつ映画タイトル名を含んでいないかを調べ、含んでいたらそのリンク url を取り出し print で出力し、終了します。
実際にやってみますと、
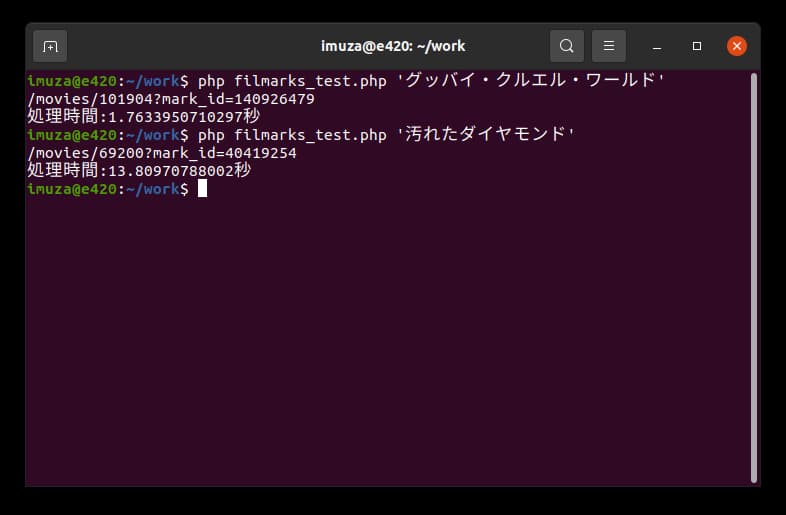
一番最初の映画「グッバイ・クルエル・ワールド」で 1.76 秒、20ページある一番最後の映画「汚れたダイヤモンド」で 13.80 秒です。時間がかかりすぎていますね。
現在レンタルサーバーは ConoHa WING を使っていますのでその環境で実際の運用方法である、ウェブページから Ajax で呼ぶ方法で測定しましたら、一番最後の映画で、
/movies/69200?mark_id=40419254
処理時間:8.9638450145721秒
約9秒という結果でした。
はてなブログでは結果を保存しておく方法がありませんでしたので毎回スクレイピングするしかなかったのですが、WordPress ですので一度取得した url はカスタムフィールドに保存する方法をとったほうがよさそうです。
であれば、過去の記事は一括で取得してすべてカスタムフィールドに保存する方法もありそうです。
いずれにしても、Heroku の Node.js サーバーの代替方法はなんとかなりそうです。
